

开放科学(资源服务)标识码(OSID): 
0 引言
径流组成成分识别是水文分析的一项重要内容,对掌握流域水资源演变规律具有重要的意义。水文学中通常假定径流序列由突变、趋势、周期性变化等确定性成分,以及将确定性成分进行分离后的随机性成分叠加组成。在径流成分识别中,首先采用时间序列的变异性诊断方法对突变、趋势和周期等演变特性进行诊断,然后选择合适的组分模型对不同变化特性的成分进行定量描述,以期充分地识别径流序列的确定性成分和变化规律。
目前关于趋势、突变和周期性的诊断识别已有较多成熟的方法,为径流序列演变特性的综合分析提供了理论基础。姜瑶等[1]基于3组不同变化特征的人工生成序列,对比分析了累积距平、线性回归等5种常用趋势检测方法的准确性和可靠性;苏翠等[2]采用Mann-Kendall趋势分析法、突变检验法和滑动T检验法,对淮河主要控制站径流进行趋势分析及突变检验;邹磊等[3]采用Mann-Kendall趋势检验法和Pettitt突变检验法分析了汉江流域典型水文站径流量的时空演变特征;冯胜航等[4]利用Mann-Kendall法及小波分析法研究了金沙江流域60 a径流量的变化趋势、周期及可能突变的年份;Yang等[5]采用线性回归、滑动平均、Mann-Kendall、Pettitt等方法分析了历史径流演变的趋势、突变、周期和内在动态规律。李艳玲[6]对渭河流域径流的周期、趋势和突变等变异性进行了检验,指出应采用多种方法对径流变化特性进行综合诊断。
在径流成分的定量识别方面,目前常采用线性叠加模型[7]对给定长度的径流序列进行突变、趋势、周期等成分的逐次提取和分离[8]。然而,针对不同组成类型和序列长度对径流成分影响的研究相对较少。覃爱基等[9]对比研究了趋势和突变提取的先后顺序,发现了趋势和突变成分之间存在明显的相互影响;于延胜等[10]采用70 a的径流资料构建了各相差5 a的6种不同长度径流序列进行成分解析,结果表明调整序列长度对径流的趋势、跳跃和周期等特征有显著的影响。前述研究仅指出了分离顺序和序列长度的变化将导致径流成分提取结果的差异,尚未能进一步探索一种合理确定径流组分模型形式的方法。谢平等[11]针对趋势和突变性同时显著存在的情景,采用基于组成成分拟合度的效率系数作为诊断准则进行具体变异形式的选择,实质是以径流序列的变异成分提取精度最大化为准则,但缺乏考虑变化长度径流序列对模型精度稳定性的影响。
为此,本文考虑突变、趋势、周期等成分的不同组成类型及序列长度对径流成分的影响,在选择多种方法进行径流特性诊断的基础上,构建不同形式的线性叠加组分模型对变化长度径流序列的组成成分进行动态识别;进而,在分析不同组分模型的识别精度及其随时间变化特征的基础上,提出基于效益风险均衡的径流组分模型选择准则。
1 研究方法
1.1 径流组分识别方法
下面介绍本文采用的突变、趋势、周期成分的识别方法,文中径流成分的拟合也称为识别或提取。
1.1.1 突变成分
将原序列按照突变点进行分段,认为第1个子序列代表天然径流序列,后续片段均为变异径流,称为变异子序列。将各变异子序列通过均值变换[17]还原至天然径流相同的均值水平,消除均值变异成分。记K个突变点将原序列分段的子序列为 ,则突变成分δk表达为
式中: 为天然子序列的均值; 为第k个变异子序列的均值。
1.1.2 趋势成分
采用Mann-Kendall法进行趋势显著性检验,采用一元线性回归方程对径流序列进行拟合,斜率和截距参数采用最小二乘回归法求解。将拟合方程中一次项作为趋势成分,即
式中:x为表示时间的因变量; 为表示趋势成分的拟合值;m为斜率参数。
1.1.3 周期成分
1.2 径流组分模型构建
1.2.1 线性叠加模型描述
设有n个样本的径流时间序列 ,由突变成分、趋势成分、周期成分、均值成分和随机成分组成,则径流组成成分的线性叠加模型描述为
式中: 分别代表突变成分、趋势成分、周期成分、剩余序列的均值,以及除去均值即中心化的随机剩余序列。将式(4)中前4项累加的序列称为“确定性成分”。若实测序列分离突变、趋势、周期性成分后的剩余序列具有自相关性,可进一步提取自相关成分叠加至确定性成分[19]。
本文突变、趋势、周期成分分别按照1.1节中的式(1)—式(3)进行提取。
1.2.2 不同组分模型形式
考虑突变和趋势成分的分离顺序及突变、趋势的不同组合方式对周期成分的影响,设计各成分识别方案如表1所示,包括突变成分识别方案2种、趋势成分识别方案2种及周期成分识别方案5种。
表1 不同分离顺序和组合方式的径流成分识别方案Table 1 Runoff component identification schemes under different separation orders and combination methods |
| 成分 类别 | 方案名称 | 分离顺序和组合方式 | 输入时间序列 |
|---|---|---|---|
| 突变 成分 | mutation | 基于实测序列识别突变成分 | |
| T-mutation | 实测序列剔除趋势项后识别突变成分 | ||
| 趋势 成分 | trend | 基于实测序列识别趋势成分 | |
| M-trend | 实测序列剔除突变项后识别趋势成分 | ||
| 周期 成分 | period | 基于实测序列的距平序列识别周期成分 | |
| M-period | 实测序列剔除突变项后识别周期成分 | ||
| m-t-period | 实测序列依次剔除突变和趋势项后识别周期成分 | ||
| t-period | 实测序列剔除趋势项后识别周期成分 | ||
| t-m-period | 实测序列依次剔除趋势和突变项后识别周期成分 |
表2 基于不同成分识别方案构建的径流组分模型Table 2 Runoff component models constructed based on different component identification schemes |
| 序号 | 模型名称 | 模型识别的确定性成分 |
|---|---|---|
| 1 | M(mut_tre_period) | 突变+趋势+周期+均值 |
| 2 | M(tre_mut_period) | 趋势+突变+周期+均值 |
| 3 | M(mut_period) | 突变+周期+均值 |
| 4 | M(tre_period) | 趋势+周期+均值 |
| 5 | M(period) | 周期+均值 |
| 6 | M(mut_trend) | 突变+趋势+均值 |
| 7 | M(tre_mutation) | 趋势+突变+均值 |
| 8 | M(mutation) | 突变+均值 |
| 9 | M(trend) | 趋势+均值 |
| 10 | M(mean) | 均值(多年平均值) |
注:模型名称M代表不同的成分类别,mean代表均值成分。为简化标记,mutation、trend简写为mut、tre,序号1~9的模型名称均省略了末尾的均值成分标记mean。 |
1.3 效益风险均衡准则
设有n个样本的实测径流时间序列 ,从实测序列中根据给定的起始点和结束点即可抽取一组径流样本序列。
将n个样本的实测序列按时序分割为长度为m和n-m个样本的两段序列,记 。以 为初始序列,逐时段增加该序列的长度,记为Xi=x1,x2,…,xm+i-1(i=1,2,…,n-m+1),直至n-m个样本均增加至 。将前述Xi(i=1,2,…,n-m+1)称为基于实测序列构造的变化长度径流样本序列。
若给定某一径流组分模型形式,可依次对变化长度的径流序列 进行“确定性成分”的识别和提取,计算确定性成分相对于实测序列的拟合精度,称为模型拟合精度,记为 ,其均值B和标准差R分别为
式中:B为模型对变化径流序列的拟合精度的平均值,代表模型在径流成分识别所取得的“效益”;R为变化径流序列下模型拟合精度的标准差,代表模型应对变化序列的稳定性,称为“风险”。
在进行模型选择时,希望模型能取得更高的精度(更小的拟合误差),同时具有尽可能小的稳定性风险。为了平衡模型的拟合精度(效益)和稳定性(风险),定义效益风险均衡指标为
式中:BR为均衡指标; 为0~1之间的权重系数;若式(5)中模型拟合精度Vi及其平均值B为极大化目标,需转化为与风险指标R相一致的极小化目标。
在进行不同形式模型比较时,可根据决策者偏好选取权重系数 进行效益和风险的平衡,进而依据“效益风险均衡指标最小”准则进行模型选择。
在应用本文所提准则时,除权重系数 可根据偏好进行设置以外,研究者还可以选择不同的模型精度评价指标和变化样本序列的构造方式。
2 应用实例分析
2.1 实例数据
金沙江流域位于长江上游,流域面积47.3万km2,具有丰富的水资源及水能资源,是我国最大的水电基地之一。在径流演变规律方面,已有针对流域上、中、下游控制站断面的研究[20]指出金沙江流域径流在1961—2010年间呈现不显著上升趋势,存在突变年份及多个显著周期,但研究工作尚未基于多种组分模型开展变化长度序列的径流成分分析。
屏山站是金沙江下游的控制性水文站,控制面积占金沙江流域的97%。本文以屏山站1956—2010年的年径流序列为实例,构造以1956年为起始年、1986—2010年为结束年的变化长度径流序列(样本数为30~55),开展不同组分模型下的径流成分识别,应用所提效益风险均衡准则进行模型选择分析。
2.2 不同模型的径流成分分析
按照1.2节表1中设计的不同组合方式下突变、趋势、周期等成分识别方案,采用1.1节的方法进行各成分的检验和识别,均取显著性水平α=0.05。
2.2.1 突变成分分析
采用Mutation方案(基于实测径流序列的突变识别)和T-Mutation方案(实测序列剔除趋势成分后序列的突变识别)2种方案进行变化径流序列(样本数30~55)的突变点诊断。结果显示:对于样本数为30~43的序列,2种方案均无显著突变点;对于样本数为44~51的序列,2种方案的突变点均为1998年;对于样本数为52~55的序列,Mutation方案(实测序列)显著突变点为1998年,T-Mutation方案(剔除趋势项的序列)无显著突变点。
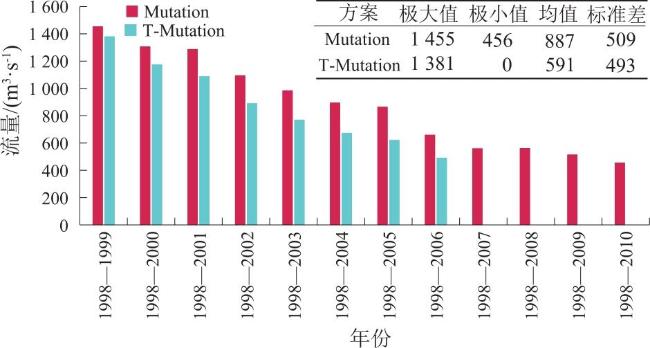
2.2.2 趋势成分分析
采用Trend方案和M-Trend方案2种方案进行变化径流序列(样本数30~55)的趋势检验和趋势成分识别。显著性检验结果为变化径流序列在Trend和M-Trend 2种方案下均存在不显著性上升或下降趋势。
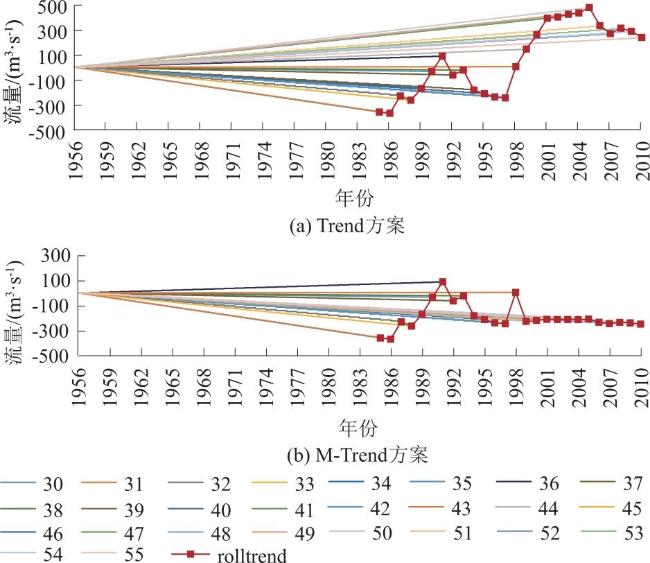
2.2.3 周期成分分析
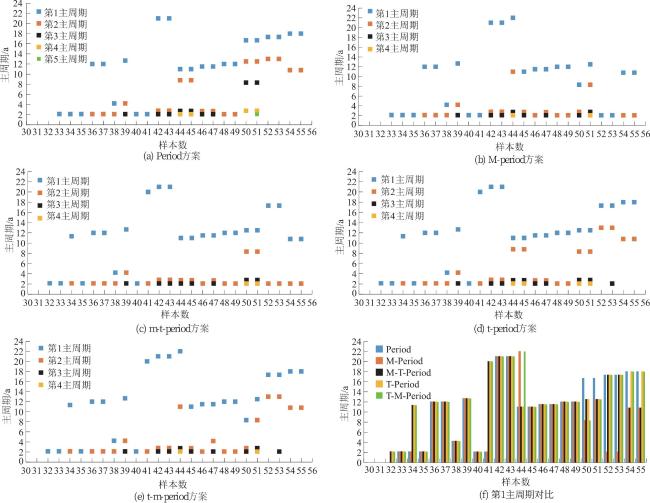
2.3 不同模型的拟合效果分析
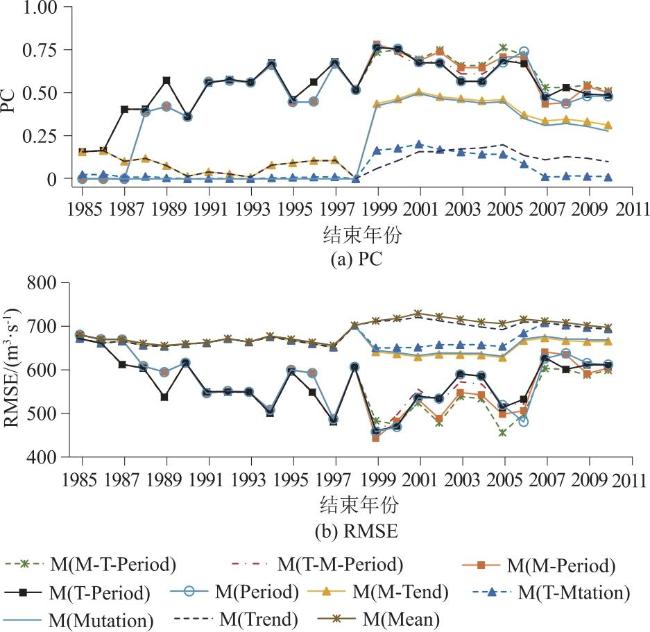
运用1.2.2节表2中10种组分模型进行变化径流序列的确定性成分提取。选择皮尔逊相关系数(Pearson Correlation Coefficient,PC)、均方根误差(Root Mean Square Error,RMSE)评价模型所识别的“确定性成分”相对于实测序列的拟合精度。拟合精度指标PC和RMSE随样本结束年份(1985—2010年)的变化过程如图4所示。结果显示:①从拟合精度看,不同模型的拟合精度指标存在差异,总体拟合效果为含周期成分的模型和仅含趋势项或突变项的模型均优于多年平均值模型;在组成成分相同时,先提取突变成分的拟合效果较先提取趋势成分更优。②从拟合精度波动情况看,不同模型的PC和RMSE均随序列长度呈现不同程度的波动,包含周期项的模型所识别的确定性成分,拟合精度波动相对更大。
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
为量化不同模型的精度指标及其波动大小,计算26组变化径流序列精度指标的均值和标准差,如表3所示。比较不同模型均值和标准差之间的关系可知:平均拟合精度越高的模型,其精度的标准差相对越大,即模型随序列长度变化的稳定性越低。
表3 不同模型的变化径流序列拟合精度统计指标Table 3 Statistical indicators of fitting accuracy for variable runoff sequences across different models |
| 模型名称 | 均值 | 标准差 | ||
|---|---|---|---|---|
| PC | RMSE/ (m3·s-1) | PC | RMSE/ (m3·s-1) | |
| M(m-t-period) | 0.56 | 557 | 0.16 | 59 |
| M(t-m-period) | 0.54 | 567 | 0.15 | 55 |
| M(M-period) | 0.57 | 569 | 0.13 | 65 |
| M(t-period) | 0.54 | 568 | 0.15 | 56 |
| M(Period) | 0.56 | 575 | 0.12 | 63 |
| M(M-trend) | 0.23 | 658 | 0.18 | 17 |
| M(T-mutation) | 0.18 | 669 | 0.15 | 18 |
| M(mutation) | 0.40 | 661 | 0.08 | 17 |
| M(trend) | 0.11 | 684 | 0.05 | 23 |
| M(mean) | — | 689 | — | 25 |
2.4 不同准则的模型选择分析
表4 基于不同权重系数 的模型效益风险均衡指标对比Table 4 Comparison of benefit-risk balance indicators for models based on different weighting coefficients |
| 精度指标 | 模型名称 | 不同权重系数 的模型效益风险 均衡指标对比 | ||||
|---|---|---|---|---|---|---|
| 0 | 0.2 | 0.5 | 0.8 | 1 | ||
| PC | M(m-t-period) | 0.16 | 0.02 | -0.20 | -0.42 | -0.56 |
| M(t-m-period) | 0.15 | 0.01 | -0.20 | -0.40 | -0.54 | |
| M(M-period) | 0.13 | -0.01 | -0.22 | -0.43 | -0.57 | |
| M(t-period) | 0.15 | 0.01 | -0.20 | -0.40 | -0.54 | |
| M(period) | 0.12 | -0.02 | -0.22 | -0.42 | -0.56 | |
| M(M-trend) | 0.18 | 0.10 | -0.03 | -0.15 | -0.23 | |
| M(T-mutation) | 0.15 | 0.08 | -0.02 | -0.11 | -0.18 | |
| M(mutation) | 0.08 | -0.02 | -0.16 | -0.30 | -0.40 | |
| M(trend) | 0.05 | 0.02 | -0.03 | -0.08 | -0.11 | |
| RMSE | M(m-t-period) | 59 | 159 | 308 | 457 | 557 |
| M(t-m-period) | 55 | 157 | 311 | 465 | 567 | |
| M(M-period) | 65 | 166 | 317 | 468 | 569 | |
| M(t-period) | 56 | 158 | 312 | 466 | 568 | |
| M(period) | 63 | 165 | 319 | 473 | 575 | |
| M(M-trend) | 17 | 145 | 338 | 530 | 658 | |
| M(t-mutation) | 18 | 148 | 344 | 539 | 669 | |
| M(mutation) | 17 | 146 | 339 | 532 | 661 | |
| M(trend) | 23 | 155 | 354 | 552 | 684 | |
| M(mean) | 25 | 158 | 357 | 556 | 689 | |
注:加粗的指标代表当前 下的最优模型。 |
表4中权重系数 从0~1变化,代表效益B的权重逐渐增加、风险R的权重逐渐减小。基于“效益风险均衡指标最小”准则进行模型优选,结果显示:当考虑风险指标最小( )时,PC推荐模型为M(Trend),RMSE推荐模型为M(Mutation)和M(M-Trend);当 时,PC推荐模型为M(Mutation)和M(Period),RMSE推荐模型为M(M-Trend);当α=0.5~1,PC和RMSE推荐模型分别为M(M-Period)和M(M-T-Period)。
可以看出,精度指标类型和权重设置不同可能得到不同的模型优选结果。所选实例中,若决策目标为拟合更充分,则优先选择依次分离突变、周期项的模型;若决策目标为精度随序列长度变化更稳定,则仅识别突变和(或)趋势项的模型更加优越。
相比较而言,若仅依据单一长度径流序列的识别精度进行组分模型选择,由于缺乏对模型稳定性的考量,将难以适用于变化条件下径流组分的提取。
2.5 实例分析结果
以屏山站1956—2010年径流为实例的应用分析结果表明:
(1)径流序列的突变、趋势、周期等各成分之间存在一定的相互消减现象,因此对于同一径流序列可采用多种模型描述不同的径流成分组成形式。
(2)径流成分识别受到模型形式和序列长度的共同影响,精度越高的径流组分模型,其识别结果随着序列长度变化的稳定性越低。如含周期成分模型的拟合精度和仅含趋势或突变项的模型均优于多年平均值模型,精度变化的稳定性则与之相反。
(3)运用所提效益风险均衡准则,可综合考虑模型精度和稳定性的偏好进行模型优选。但精度和稳定性指标的定义及偏好权重设置的不同,均可能得到不同的模型优选结果。
3 结束语
本文针对目前径流组分识别中模型形式难以确定的问题,关注到径流成分及识别精度受模型函数和序列长度的共同影响,在已有径流成分提取方法分析不同模型的识别精度及其随时间变化稳定性的基础上,提出了基于效益风险均衡的径流组分模型优选准则。以屏山站1956—2010年径流为实例对所提准则进行应用分析,验证了其适用性。该准则为径流组分模型选择提供了一种均衡考量模型效益和风险的新思路,便于决策者在变化条件下综合考虑其对模型精度和稳定性的偏好进行模型优选。
所提准则中精度和稳定性指标可根据决策需求进行灵活定义,也可推广至其他实例进行应用。